



データサイエンティスト
2024/03/01
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…
![]()
INDEX
データサイエンスが学べる
日本屈指のビジネススクール「datamix」
データサイエンス
2020.02.07
<半年でデータサイエンティストを目指す>
教育給付金で最大70%還付対象講座のご案内。
◆今回は、データサイエンス(Data Science)とは?を考えてみました。
まずは、ウィキペディアによる定義をみてみました。
以下に引用しますが、定義ともなると哲学的です! データを活用して社会にとって有益なアプローチをする、要は「データから我々が豊かになる方法を学問すること」といったところでしょうか。なんだか素敵なものにみえてきます。
「データサイエンス(data science)とは、データを用いて新たな科学的および社会に有益な知見を引き出そうとするアプローチのことであり、その中でデータを扱う手法である情報科学、統計学、アルゴリズムなどを横断的に扱う。データサイエンスを、統計的、計算的、人間的視点から俯瞰することができよう。それぞれの視点がデータサイエンスを構成する本質的な側面であるが、これらの3つの視点の有機的結合こそがデータサイエンスという学問の神髄である。これまでのデータ解析における現場の知識の重要性に対する認識不足が、データサイエンスという学問に対する幅広い誤解の源泉であると考えられる」
引用元:https://ja.wikipedia.org/wiki/データサイエンス(2020.02.06)
次は、簡単にデータサイエンスという言葉の歴史経緯を少し振り返ってみます。
「データサイエンス」は比較的新しい言葉で、いくつかのバズワードを変遷して出てきました。
デンマークのコンピュータ科学者であるピーターナウアが1974年に出版した「Concise Survey of Computer Methods」の中で「データサイエンス」という言葉を繰り返し使用したのが一般的にはデータサイエンスの歴史の始まりとされています。
その後1980年代までは、データサイエンスという言葉の定義が議論されたり、研究により新たな手法が開発されたりしながら、徐々に一つの研究分野として確立していきます。
1990年代頃から、大規模化の進むデータセットからパターンを見つけるプロセスを表す用語として、「Knowledge Discovery(知識発見)」 や「Data Mining(データマイニング)」という用語がよく使われるようになりました。
機械学習のアプローチも知識駆動型のアプローチからデータ駆動型のアプローチへと移行するようになり、この1990年代頃から現在のデータサイエンスへと続く流れが見え始めてきます。
現在データ分析や機械学習などでよく利用されるプログラミング言語Pythonも1990年に誕生しました。
1994年にはBusinessWeek誌で「データベース・マーケティング」という言葉が表紙を飾り巻頭特集が組まれました。これがデータを活用する現代のマーケティングの初期の形のあらわれといわれています。
1990年代後半になるとデータマイニングへの注目はさらに高まってきます。
1996年に発表された論文で「データマイニング」の言葉の定義・基本機能・処理手順が提案されたことで、データマイニングの研究分野が明確に定義され、研究や活用がこれまで以上に盛んに行われるようになります。
1999年 Knowledge@Wharton誌に記載された「従来の統計的手法は小さなデータセットではうまく機能するが、データマイニングではスケーラビリティが問題、ウェブサイトの意思決定に対処するために特別なデータマイニングツールを開発する必要がある」という言葉は、2000年代以降のビッグデータ時代の到来を予感させました。
2000年代に入ると、
2001年にはWindows XPが発売され、言葉としてSaaS(Software-as-a-Service)も誕生しました。
2000年代から少しずつ、個人がパソコンを所有したりと生活にインターネットが入り込んでくるようになります。世界中でやり取りされるデータ量が増大していきます。
2006年、オートエンコーダを利用したディープラーニングが発明されます。ここが、人工知能にとっての大きなブレイクスルーとなりました。
この2006年にはHadoopの最初のバージョンであるHadoop 0.1.0 がリリースされます。
また、レコメンドエンジンの重要性に以前より注目していたNetflixがデータ解析コンペNetflix Prizeを開催するなど、現在のデータサイエンスブームへとつながる最初の一歩を踏み出した年といえそうです。
たびたび人工知能の話で話題にあがる、2045年までにシンギュラリティ(技術的特異点:人口知能が人間の知能を超越する)を迎えるという説を「THE SINGURARITY IS NEAR(シンギュラリティは近い)」という本でレイ・カーツワイルが発表したのもこの頃です。
Webサービスにおいても2004年にFacebook、2005年にYoutube、2006年にTwitterがサービスを開始。2007年にはiPhoneが発売と、インターネットやITなど、現在の私達の生活の中で必要不可欠となっていることの多くが2000年代に誕生しました。同時にデータ量の増大も意味しています。
以降、データ分析やデータによる意思決定、データを活用したマーケティングなど、蓄積されたデータ活用の重要性が増していきます。
2008年 当時データアナリティクス分野の業務をリードしていたDJ Patil(LinkedIn)とJeff Hammerbacher(Facebook)が「データサイエンティスト」という肩書きを名乗り始めます。Googleなど他の企業で同様の仕事をしていた人達も自称するようになり、当時のバズワードになりました。
2010年、インターネットを流れるデータ転送量の増大を受けて、ビッグデータという用語が提唱されました。kaggleがサービスを開始した年でもあります。
影響を受け、2011年にはデータサイエンティストの求人情報が15,000%も増加したといわれています。
2012年。
データサイエンスの歴史の中で、大きな転機を迎えます。
ハーバード・ビジネス・レビュー誌が「データサイエンティストは21世紀で最もセクシーな職業(Data Scientist:The Sexiest Job of the 21st Century)」と題する記事を掲載しました。この記事をキッカケに職業としての「データサイエンティスト」への注目が大きく高まり、認知度も一気に上がりました。
また、この2012年に行われたILSVRC(画像認識の精度を競う大会)で優勝したカナダのチームが、ディープラーニング(深層畳み込みニューラルネットワークを利用したもの)を採用して目覚ましい成果をあげます。カナダチームの活躍でディープラーニングの技術に注目が集まり、現在まで続くAIブームの始まりともなりました。
以降、ディープラーニングに関する研究は加速し急速に普及していきます。
データサイエンスの役割の幅が広がり、データサイエンティストの需要も高まっていった事で、データサイエンスとして学ぶ内容は多様化し、データサイエンティストが業務上で求められるスキルも細分化されるようになった様子が、歴史からはみえます。
細分化された故に、関わる状況により人によってデータサイエンスの意味合いも違う、と想像できます。データサイエンスの言葉の定義を難しくしている背景の一つでしょう。
データサイエンスとは何か。今度は、データサイエンスの専門家であるデータサイエンティストが行っている仕事から紐解いてみたいと思います。
会社の規模や組織によって違いはあると思いますが、アマゾンやツイッターで働いた経験をもつデータサイエンティストに聞いてみました。データサイエンティストは以下のようなタスクをこなしているそうです。
1. ユーザーの行動や会社の取引などのログをデータとして蓄積・整理する
2. 整理されたデータから必要な情報を抽出する
3. データを可視化する
4. データを分析する
5. KPIや指標を定義する
6. KPIや指標をトラッキングする
7. データからの示唆(インサイト)を関係者に説明し、意思決定を促す
8. プロダクトの機能のABテストや実験(Experimentation)を行う
9. モデルを作り将来の取引量や指標を予測する
10. プロダクトにレコメンドエンジンなどの自動最適化機能を実装する
技術内容はとんでもなく違うのでしょうが、比較的、あるサービスに対してのWEBマーケティングに近いイメージがしました。企業に属すデータサイエンティストは、サービスによりできたデータを利用し、目的とする価値を実現するまでを担い、一連のデータ活用をリードする役割を持っていそうです。
データサイエンティストが役割を担うのに必要な理論・技術がデータサイエンスとも言えそうです。企業のサービスが我々の生活を豊かにしてくれるとすると、はじめに記載したウィキペディアのデータサイエンスの定義もマッチしてきそうです。
データサイエンティストの仕事を「会社がデータを作り出してから、それを利用し価値を実現するまでの一連の役割を担っている」としました。しかし実際には、会社によってデータサイエンティストの仕事内容はかなり異なります。
●ジェネレーション:ユーザーがアプリケーションを使うことで生成されるデータやサイトアクセスログ、外部と連携しているデータなど。プロダクト自体の開発と密接に関係するため、ソフトウェアエンジニアが担当していることも多い。
●ストレージ:データはログを取っているだけでは利用できないため、一言でいうとデータを使えるように蓄積し整える部分。
●アナリティクス:データ分析やABテストなど、それほど高度な技術を用いないデータの利用。
●アプリケーション:プロダクトへのレコメンドエンジンの搭載など、AIや機械学習・ディープラーニングを用いた高度なデータ利用。
また、組織の規模や会社によって、データサイエンティストに期待される役割も違いが出てきます。
1. スタートアップ
規模が小さいスタートアップの場合、データサイエンティストはいても一人か数人です。その場合、データサイエンティストは上図のほぼすべてのタスクをこなしています。エンジニアが実質兼任していることも少なくないでしょう。あまりにもカバー範囲が広いため、アプリケーションの段階まではデータ利用が進んでいないことが多いのではないでしょうか。
2. 中規模企業
100人程度以上の中規模の企業では、リソースが増えてくるので、ソフトウェアエンジニアが「ジェネレーション」、データエンジニアが「ストレージ」、データサイエンティストが「アナリティクス・アプリケーション」という具合に分担が進んでいきます。データの利用度合いもスタートアップに比べると上がっていきます。
3. 大規模企業
十分なリソースを有する大規模な企業になると、さらに分担が進みます。ソフトウェアエンジニアが「ジェネレーション」、データエンジニアが「ストレージ」というところまでは、中規模企業と同じですが、アナリティクス・アプリケーションの部分が、いかにビジネスにインパクトを引き出せるか、に関わってくるので、担っている人の数が増え、組織も複雑化します。一例としては、データサイエンス・アナリティクスチームが「アナリティクス」をデータサイエンス・リサーチチームが「アプリケーション」を担当します。前者・後者ともデータサイエンティストという肩書きを持っていることもあれば、前者をデータアナリストとか、後者をリサーチャーと言ったりもします。また、機械学習エンジニアも、エンジニアですが、組織的にはデータサイエンス・リサーチチームに属します。
技術ロールと会社の規模で「データサイエンティスト」という肩書きの人がやっている仕事は異なるようです。データサイエンティストとして転職したい人やデータサイエンティストを雇いたい人は、注意が必要なポイントでしょう。
今度は、他の分野との関係性で、データサイエンスの定義を整理してみたいと思います。
データサイエンスは分野としては若く、以下の3分野と多くの部分で重複しています。
図でまとめると以下のような感じです。
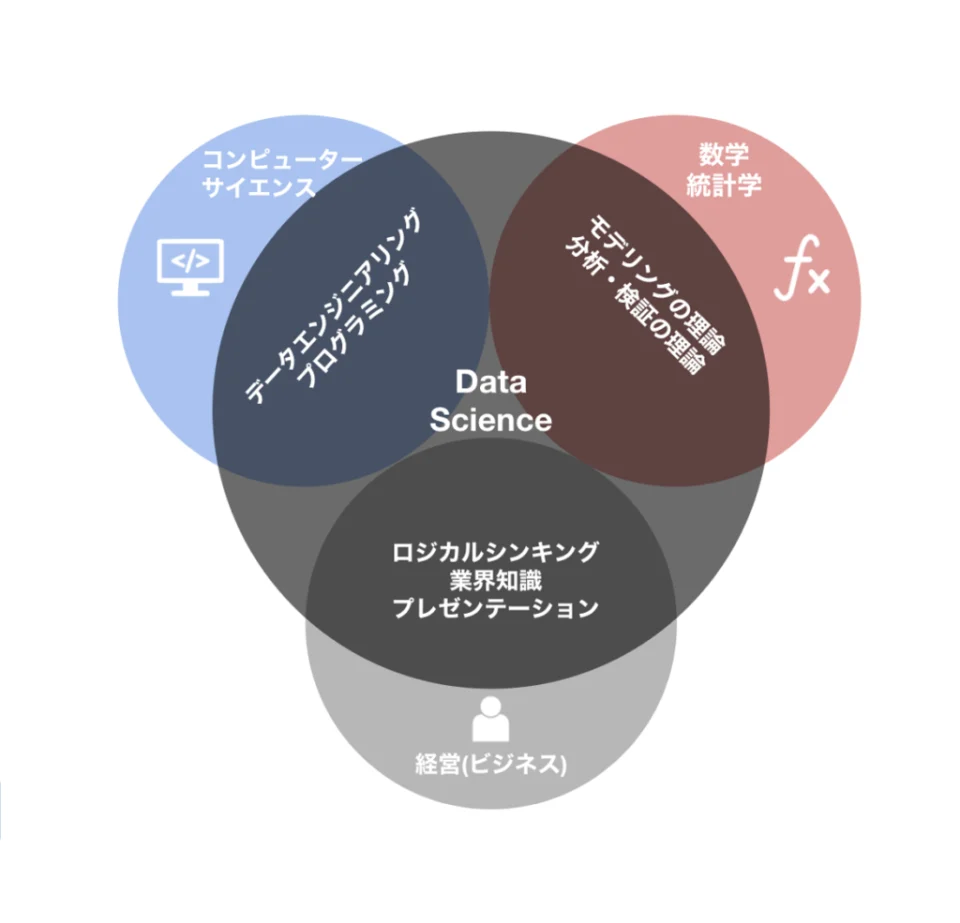
実際には、全てが得意な人は稀少です。データサイエンティストの中でも、組織や役割、個性によって、使っているスキルに濃淡があります。
企業ごとでデータサイエンスやデータサイエンティストの定義は違う、と認識すべきでしょう。
データサイエンスの有用性が多岐にわたるため、学問として細分化され、さらに人によって定義が細かく別れている状況が垣間見えます。
データサイエンスやデータサイエンティストの定義をしっかり確認するといったコミュニケーション上の注意が必要でしょう。
広義では、社会を有益にするためにデータを活用する学問がデータサイエンスであることは間違いなさそうです。
DX推進が叫ばれる中、データ人材として、データをしっかり扱えるビジネスパーソンが重要視されています。データミックスで、データサイエンスを学んでみませんか?
教育給付金で最大約70%が還付されます。
無料体験講座も開催中。
関連記事
ピックアップ
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…

データサイエンティストが資格を取得するメリットとおすすめの資格5選
データサイエンティストは、データを活用してビジネスや社会…
とは?難易度や勉強方法を解説.png)
統計検定データサイエンス基礎(DS基礎)とは?難易度や勉強方法を解説
統計検定データサイエンス基礎(DS基礎)は、データサイエ…

データサイエンスとは? 活用可能な領域や何が変わるかを解説
現代社会においては、あらゆる業界で日々膨大な量のデータが…

DX人材の育成事例とそれが急務である理由とは
情報通信白書(2022)における企業約3,000社への調…

もし営業(セールス)担当者がデータサイエンスを学んだら
データサイエンスのビジネス活用としては、データドリブン経…

データサイエンティストはなくなる職業という誤解?
データサイエンティストという職業が誕生し注目が集まり始め…

「データサイエンティスト育成のフロンティア」 立川 裕之
トップセールスからデータサイエンティストへ転身。 「人…
インタビュー
ランキングRANKING
WEEKLY週間
MONTHLY月間

