
の可能性.png)


データサイエンティスト
2024/03/01
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…
![]()
INDEX
データサイエンスが学べる
日本屈指のビジネススクール「datamix」

データサイエンス
2020.04.28
当社のデータサイエンティスト福澤がQiitaで執筆した記事について、
当コラムでもご紹介いたします!
先日リリースされた機械学習ライブラリーPyCaretを使用してみました。
誰でも簡単にモデリングができるなと実感しました。本当にめちゃくちゃ簡単でした!
10行もコードを書かずに前処理から、チューニング、予測ができます!
引数などまだ把握できていない部分が多くありますが、PyCaretの記事を1番に書こうと思い書きました。
早速ですが、先日リリースされた機械学習ライブラリーPyCaretを使用してみました。
誰でも簡単にモデリングができるなと実感しました。本当にめちゃくちゃ簡単でした!
10行もコードを書かずに前処理から、チューニング、予測ができます!
引数などまだ把握できていない部分が多くありますが、PyCaretの記事を1番に書こうと思い書きました。
PyCaret 1.0.0
Google Colaboratory
下記のコードを実行しインストールします。
体感ですが、2,3分で終わりました。
ローカルでインストールしたらエラーが出てきたので、一旦断念しています。
! pip install pycaret
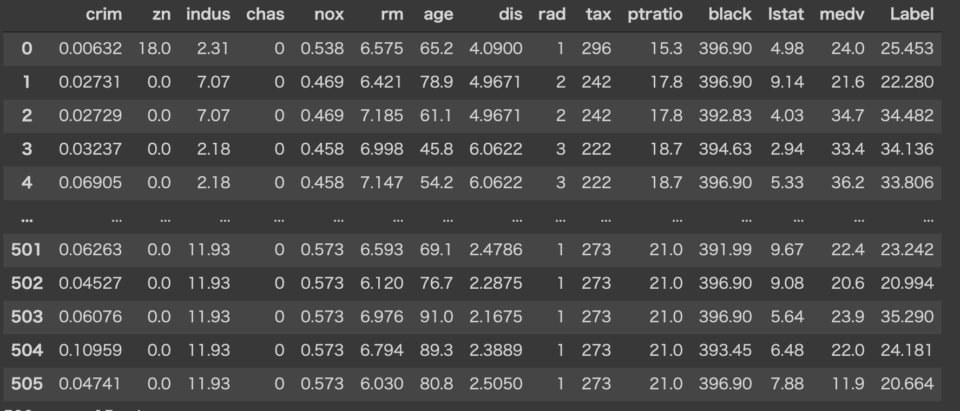
今回はbostonのデータを使用していきます。以下のコードでデータを取得できます。

前処理を行います。
setup()にデータとターゲット変数を定義し、初期化しています。
今回は回帰問題を解くので、
pycaret.regression を指定しています。
分類問題の場合は、
pycaret.classification を指定してください。
自然言語処理、クラスタリングなどのタスクを行うこともできます。
setup()は欠損値処理や、カテゴリーデータのエンコーディング、train-test-splitなどを行なってくれます。
詳しくは、
こちらを参照ください。
実行するとセットアップが完了します。
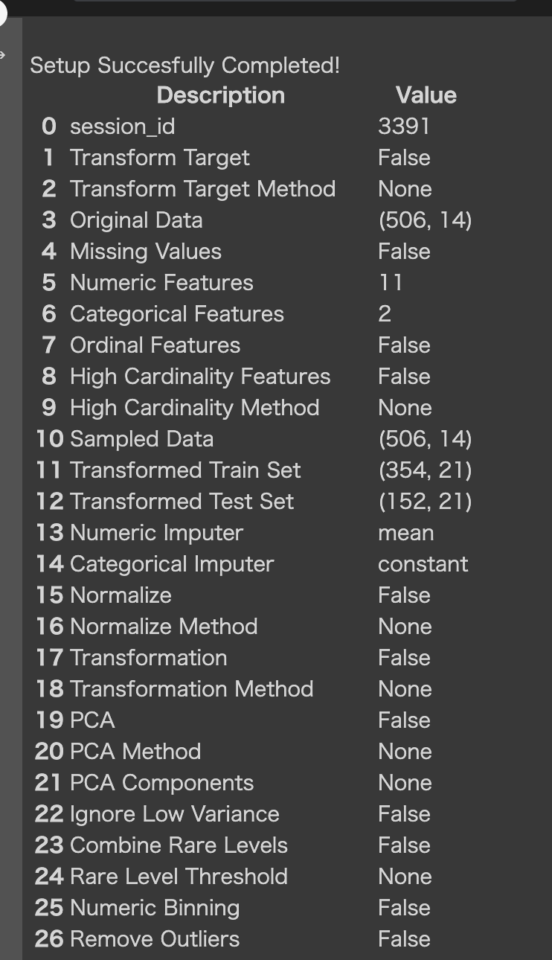
モデルの比較し選択していきましょう。
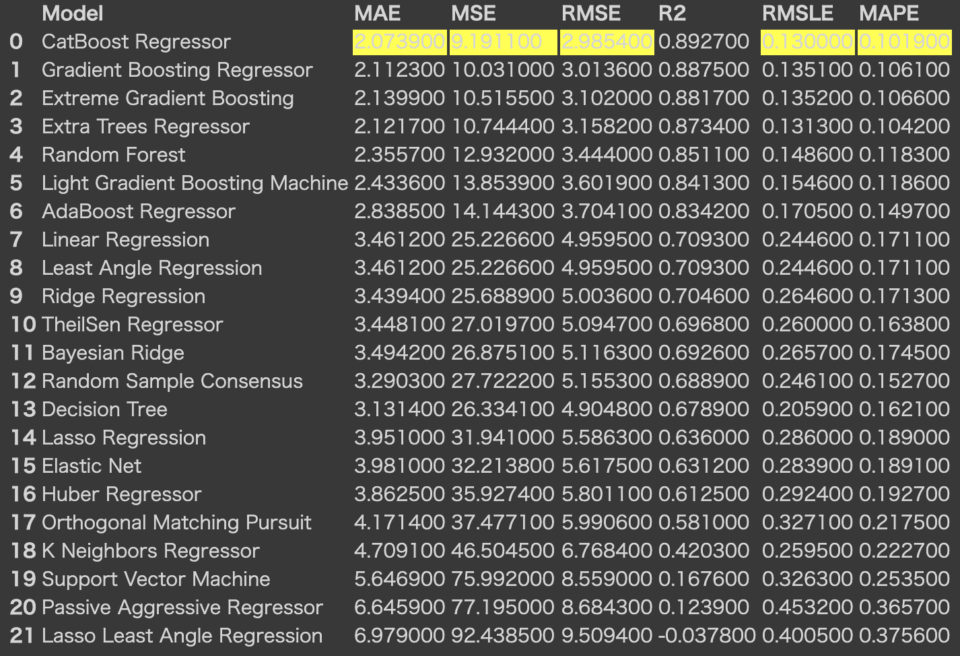
モデルの比較については、下記の1行で行えます。2、3分で終了しました。
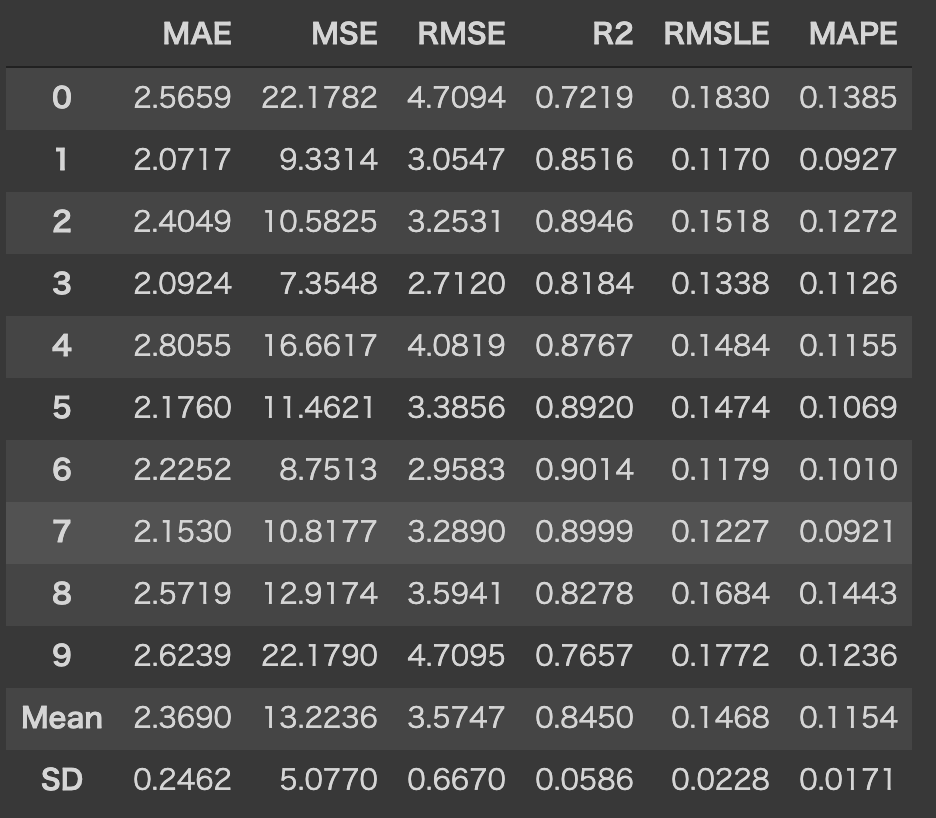
評価指標も一覧で確認できて便利ですね!デフォルトで、k-foldを10分割で行なっています。引数で、fold数や、ソートする指標を指定できます。(実行はデフォルトで行なっています。)
実行結果はこちら
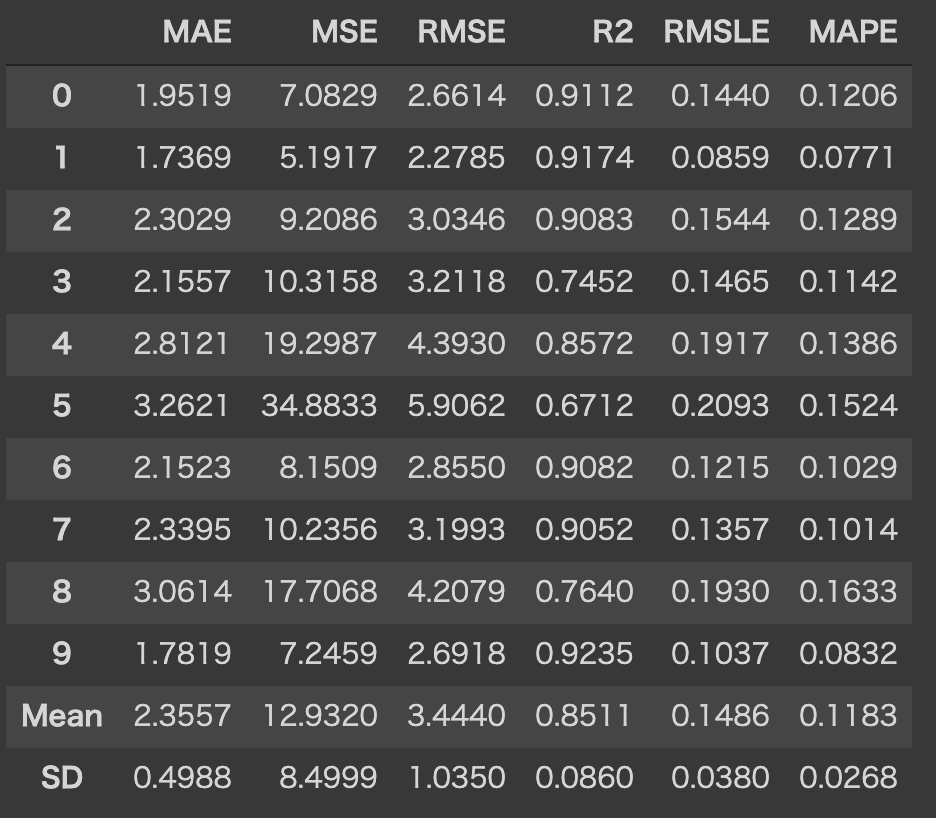
モデルを選択してモデリングを行います。今回はRandom Forestを使用しています。(完全に気分ですね。)
この関数は、k-foldしたスコアとトレーニング済みモデルオブジェクトを含むテーブルを返します。
SDも確認できてとても便利ですね!
トレーニング済みオブジェクトの後ろにピリオドで指定することで、下記に様に確認できます。
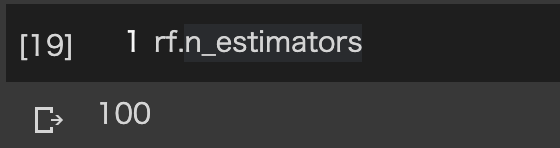
チューニングも1行で行えます。
パラメータの取得は下記でできます。

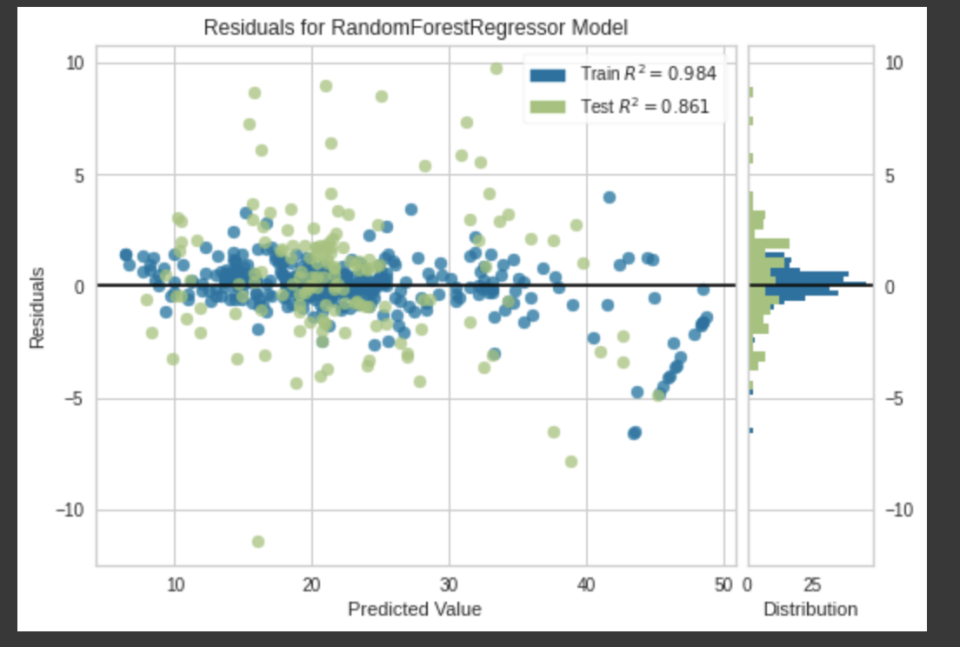
モデルの精度を可視化してみましょう。回帰のプロットは以下の図ですが、分類問題の場合は、指標に合わせてアウトプットを選択できます。
分類問題の可視化のバリエーションが豊富なので、ここにきて分類問題を選択しておけばよかったと少し後悔しました。。。
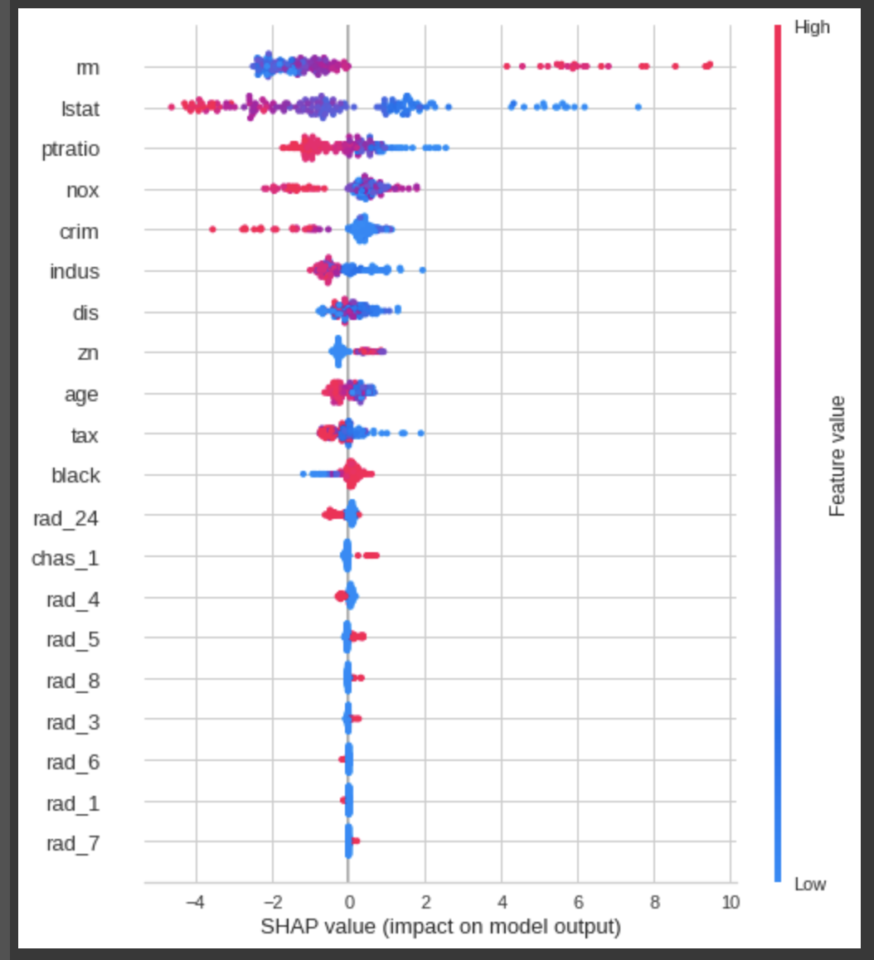
モデルの解釈はSHAPを用いて行なっております。
グラフの見方や、モデルの解釈方法については、SHAPのgitを確認ください。
testデータに対しての予測は下記の様に書きます。
実行結果は、setup()でtrain-test-splitした30%のテストデータに対して予測した結果を返してくれます。
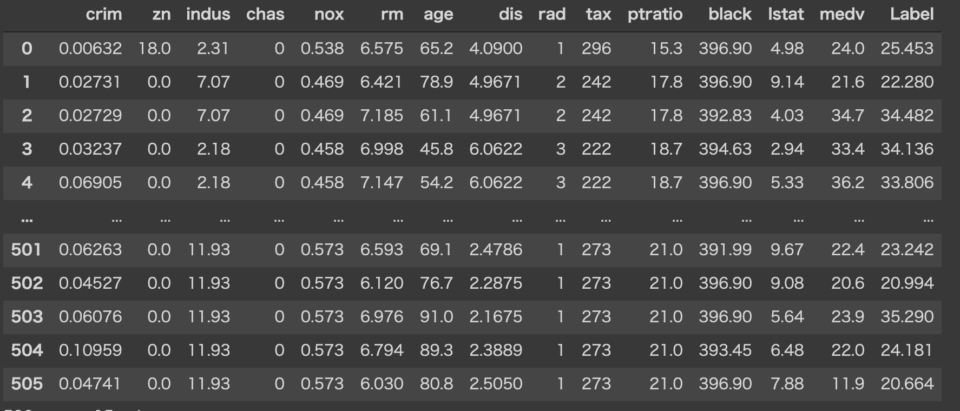
新たなデータに対して予測を行う際には、dataの引数にデータセットを渡します。
※今回は元のデータを使い回しています。
一番右に予測結果が追加されます。
最後までお読みいただきありがとうございました。
Announcing PyCaret 1.0.0
PyCaret
PyCaret git
SHAP git
Pythonのライブラリ「PyCaret」についてご紹介しました。
当社ではデータサイエンティスト育成コースを始めとするデータサイエンス分野の講座や各種イベントを開催しております。
データミックスにご興味のある方は、ぜひ説明会にお申込みください!
お申込はこちらからお願いします。
関連記事
ピックアップ
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…

データサイエンティストが資格を取得するメリットとおすすめの資格5選
データサイエンティストは、データを活用してビジネスや社会…
とは?難易度や勉強方法を解説.png)
統計検定データサイエンス基礎(DS基礎)とは?難易度や勉強方法を解説
統計検定データサイエンス基礎(DS基礎)は、データサイエ…

データサイエンスとは? 活用可能な領域や何が変わるかを解説
現代社会においては、あらゆる業界で日々膨大な量のデータが…

DX人材の育成事例とそれが急務である理由とは
情報通信白書(2022)における企業約3,000社への調…

もし営業(セールス)担当者がデータサイエンスを学んだら
データサイエンスのビジネス活用としては、データドリブン経…

データサイエンティストはなくなる職業という誤解?
データサイエンティストという職業が誕生し注目が集まり始め…

「データサイエンティスト育成のフロンティア」 立川 裕之
トップセールスからデータサイエンティストへ転身。 「人…
インタビュー
ランキングRANKING
WEEKLY週間
MONTHLY月間

