



データサイエンティスト
2024/03/01
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…

データサイエンス
2020.03.25
機械学習徹底解説①では、機械学習の概要についての話を書きました。
今回は機械学習の3つの学習法である「教師あり学習」・「教師なし学習」・「強化学習」について説明していきます。
機械学習の勉強を始めると必ずと言っていいほどに、最初に勉強するのが教師あり学習/教師なし学習です。
教師あり学習ではデータに正解となるラベルを付けて機械に学習させます。機械に正解が何かを学習させ、その正解に対しての精度を高めるようにしていきます。正解のデータ(=教師)があり、その正解を機械に教えて学習させるため、教師あり学習です。
教師なし学習ではデータにラベルを付けず、与えられたデータを元に機械が自律的にルールや特徴を学習します。
教師あり学習とは逆に学習させるデータに人間が与える正解が存在しないため、教師なし学習です。
学習させるデータも教師あり学習では「教師データ」、教師なし学習では「学習データ」と区別して呼びます。
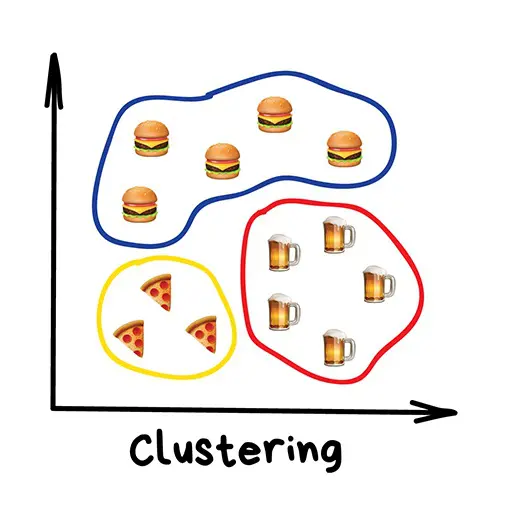
分類とクラスタリング
機械学習の大きな機能の一つがデータをカテゴライズする事です。
これを教師あり学習では「分類」、教師なし学習では「クラスタリング」と言います。一体何が違うのでしょうか?
教師あり学習における分類では、人間の手でデータに一つ一つラベル付けをし、それを元にルールや確率などによりデータを分類します。教師あり学習による分類の活用例として最も有名で身近なのはスパムメールの自動フィルタリングです。教師あり学習の手法としては、決定木・ロジスティック回帰・k近傍法・SVM(サポートベクターマシン)などが一般的です。
教師なし学習におけるクラスタリングとは、入力データを元に、機械が特徴量などを元に似た者同士をグルーピングしていくことでデータの分類をします。ラベル付けの必要はありません。教師なし学習によるクラスタリングの活用例としては、Apple PhotoやGoogle Photo、Facebookなどでの自動で顔を認識して人物を特定する機能が(かなり複雑なものですが)このクラスタリング技術によるものです。
手法としてはk-meansクラスタリング(k平均法)・MeanShift・DBCANなどが有名です。
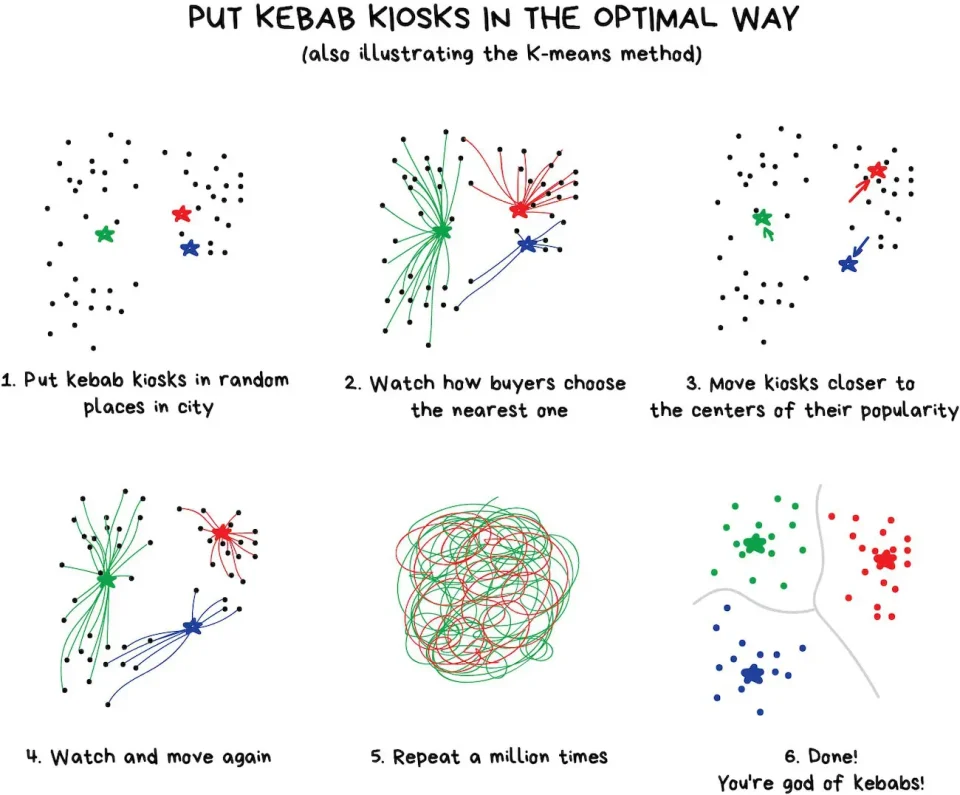
参照元:http://vas3k.com/blog/machine_learning/
回帰
回帰は教師あり学習で使われる予測の方法で、プロットしたデータに関係性を表す線を見出します。そして、その傾向を元に今後の数値を予測します。回帰によって予測されるものは数値のみです。
回帰は株価や売上の予測などに使われます。
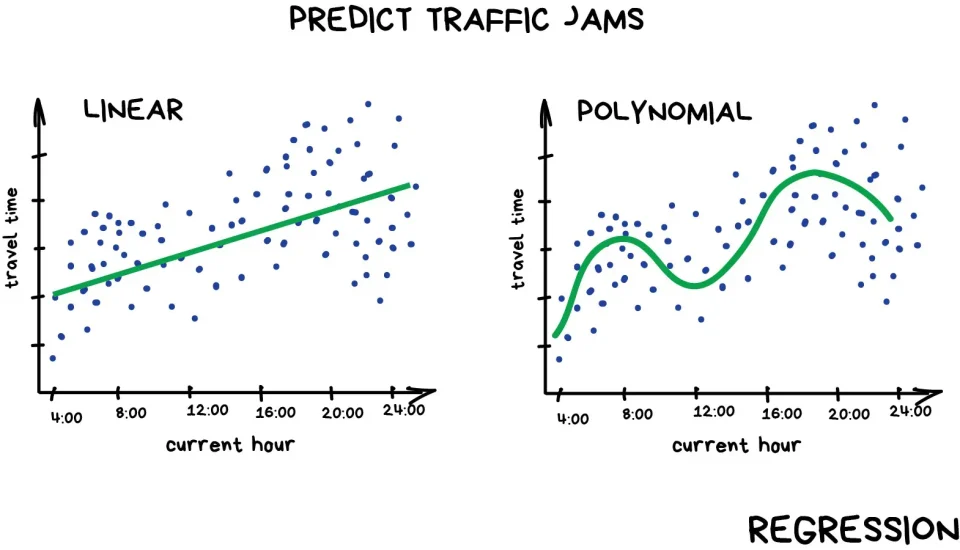
参照元:http://vas3k.com/blog/machine_learning/
次元削減
次元削減は教師なし学習で使用されるアルゴリズムを支援するテクニックです。
機械学習で使われる「次元」とは①の記事の機械学習に必要な3つの要素(後でリンク)の②で触れている特徴量の事を指します。私たちが普段使う、平面空間の2次元・立体空間の3次元とは意味が異なるので注意が必要です。
機械学習で使うデータの情報量は出来るだけ多い方が良いと考えるかもしれません。
実際に何らかの予測をする際に、判断材料となる要素(学習データの特徴量)が2つだけの場合と、20、30とある場合、特徴量が多くなるほどに予測精度が高くはなるの事実ですが、その分機械が認識すべきパターンや計算量が指数関数的に増えてしまいます。また、その分必要とされる学習データの量は多くなり、学習の難易度も格段に高くなってしまいます。(これを次元の呪いと言います)
そこで、このような場合には特徴量を可能な限り最低限の数にして次元の呪いを回避する=次元削減が必要となります。
①の記事の機械学習に必要な3つの要素(後でリンク)の②で触れているで少し触れている「特徴量選択」というのはこの次元削減の一つです。
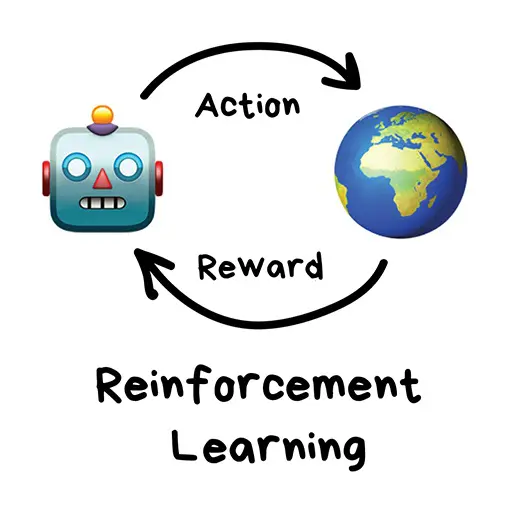
強化学習とは、「報酬」を得るために自ら学んで賢くなっていく機械学習の手法です。
ある状態において、ある行動をとったときの結果ごとに報酬を設定し価値を最大化させるように機械が探索し学習して精度を上げていくのが強化学習です。
システム制御などに向いているため、株やFXの自動売買や自動運転技術に利用されているほか、エレベーター制御での利用なども検討され始めています。
強化学習で有名なアルゴリズムはQ-Learning・SARSA・DQN・A3C・遺伝的アルゴリズムなどです。
参照元:http://vas3k.com/blog/machine_learning/
スーパーマリオやテトリスなどの有名ゲームをAIがプレイする動画が一時期流行ったのはご存知でしょうか?
全てではないかもしれませんが、こういった動画の多くの人工知能では強化学習が使われています。
「報酬」を得るために自ら学んで賢くなっていく
という強化学習の説明が一番分かりやすいのは、プレイを繰り返すほどにより短時間やより高得点をあげてAIがゲームをプレイする動画かもしれません。
こちらの動画などは分かりやすく解説されています。
数年前に囲碁で人間に勝ったことが大きな話題を呼んだAlphaGoという人工知能でも強化学習が使われていますが、こちらは比較的最近に登場した「深層強化学習」と呼ばれる、強化学習とディープラーニングを合わせた手法になります。
深層強化学習については、次回の記事でニューラルネットワークとディープラーニングについて説明する時に改めてご紹介したいと思います。
関連記事
ピックアップ
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…

データサイエンティストが資格を取得するメリットとおすすめの資格5選
データサイエンティストは、データを活用してビジネスや社会…
とは?難易度や勉強方法を解説.png)
統計検定データサイエンス基礎(DS基礎)とは?難易度や勉強方法を解説
統計検定データサイエンス基礎(DS基礎)は、データサイエ…

データサイエンスとは? 活用可能な領域や何が変わるかを解説
現代社会においては、あらゆる業界で日々膨大な量のデータが…

DX人材の育成事例とそれが急務である理由とは
情報通信白書(2022)における企業約3,000社への調…

もし営業(セールス)担当者がデータサイエンスを学んだら
データサイエンスのビジネス活用としては、データドリブン経…

データサイエンティストはなくなる職業という誤解?
データサイエンティストという職業が誕生し注目が集まり始め…

「データサイエンティスト育成のフロンティア」 立川 裕之
トップセールスからデータサイエンティストへ転身。 「人…
インタビュー
ランキングRANKING
WEEKLY週間
MONTHLY月間

