




データサイエンティスト
2024/03/01
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…

データサイエンス
2021.09.22
データサイエンスと聞くと、「ほとんどの人が難しそう」「数学が必要なんでしょ?」「プログラミングもやったことないし・・・」というリアクションをします。しかし、データサイエンスの大事なところは、プログラミングでも数学でもありません。それらのデータサイエンスに取り組むためのスキルであって、練習すればできるようになります。それよりももっと大切なことがあります。それは、好奇心です。
今日のテーマは「身近なデータとの対話から世界を覗く」ですので、タイトル通り、世界に目を向けて見たいと思います。
世界の話題と言えば、やはりコロナです。なかなか海外旅行に行けない中、ニュースや旅番組で世界情勢を見ていると、本当にいろいろな国があります。
「他の国の暮らしってどのようなものなのだろう?」
そんな疑問が頭によぎります。そこで少し調べてみると、世界幸福度ランキングという調査があります。今回は、そのデータを使って、世界の国の様子を見てみましょう。
使用するデータ:World Happiness Report 2021
https://worldhappiness.report/ed/2021/
Q. 早速ですが、2020年でトップ3の国はどこでしょう?
A. 北欧の国々が上位を占めています。
第1位 フィンランド
第2位 アイスランド
第3位 デンマーク
想像通りでしたか?ちなみに、幸福度というとブータンを想像する人も多いと思います。私も気になって調べて見たところ、調査には含まれていないようです。
さて、幸福度データには、以下のようなデータもあります。
・Life Ladder
幸福度(10点満点)
・Log GDP per capita
1人あたりGDPの対数。
国の経済的な豊かさを示している。
・Social support
「困った時に頼れる親戚や友人がいるか?」という質問に対してYesと答えた人の割合
・Healthy life expectancy at birth
健康寿命(WHOのデータから引用)
・Freedom to make life choices
「人生を選択する自由に満足していますか?」という質問に対するYesと答えた人の割合
参考:https://happiness-report.s3.amazonaws.com/2021/Appendix1WHR2021C2.pdf
Q. 上記のデータと幸福度(Life Ladder)との間に、どのような関係があるでしょうか?
A. こんな時にデータサイエンティストなら、散布図を描きます。ちなみに、この散布図を並べたものを「散布図行列」と言います。
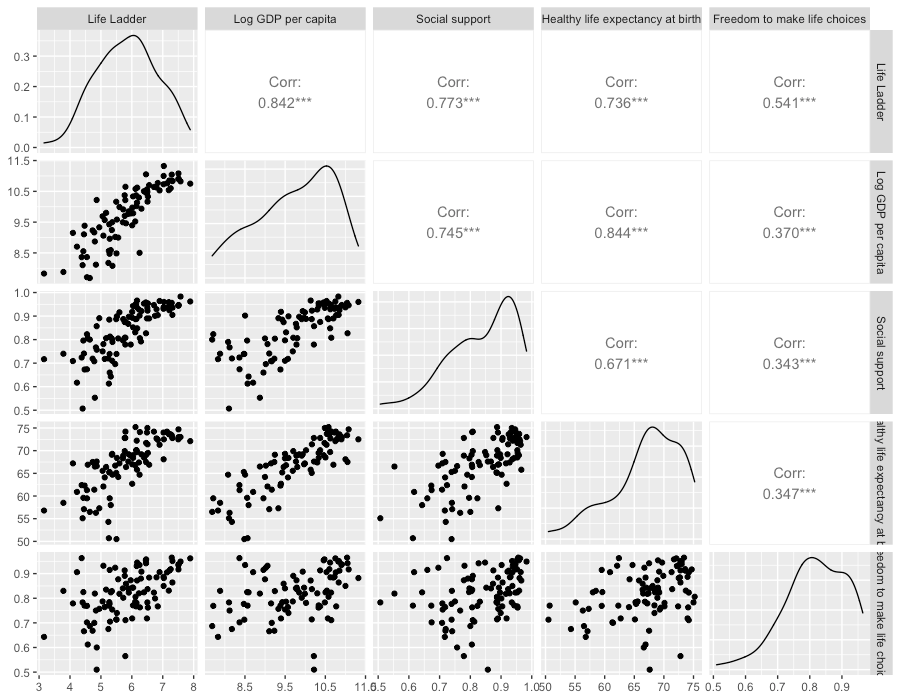
一番左の列を見てください。
「幸福度 = Life Ladder」と、上から
・Log GDP per capita = 1人あたりGDPの対数。国の経済的な豊かさを示している。
・Social support = 「困った時に頼れる親戚や友人がいるか?」という質問に対してYesと答えた人の割合
・Healthy life expectancy at birth = 健康寿命(WHOのデータから引用)
・Freedom to make life choices = 「人生を選択する自由に満足していますか?」という質問に対するYesと答えた人の割合
との関係を表しています。
これらの散布図をみると、
・「Log GDP per capita = 1人あたりGDPの対数」との相関関係は強そう。
・「Social support = 頼れる親戚や友人がいるか」との相関関係も強そう。
・「Healthy life expectancy at birth = 健康寿命」との相関関係も強そう。
・「Freedom to make life choices = 人生の自由度」との相関関係も強そう。
経済的に豊かで、頼れる親戚や友人がいて、健康で長生きできて、人生の自由度もある、そうしたら、幸福だ!というように見えます。このように、データから、経済的な豊かさ、健康寿命、頼れる親戚・友人の有無どうしも密接な関係がありそうだということがわかります。「ふーん・・・」で終わってはいけません。もっとデータをよく眺めていきます。
例えば、
・「Log GDP per capita = 1人あたりGDPの対数」と「Social support = 頼れる親戚や友人がいるか」の散布図をみると、強い相関がありそうです。
・「Log GDP per capita = 1人あたりGDPの対数」と「Healthy life expectancy at birth = 健康寿命」も同様に相関がありそうです。
・「Social support = 頼れる親戚や友人がいるか」と「Healthy life expectancy at birth = 健康寿命」も上記2つの比べるとやや傾向が見えにくいですが、それでも相関関係はありそうです。
これらの傾向から、何か気になることはありますか?そもそも、経済的な豊かさ、健康寿命、頼れる親戚・友人の有無の間には関係があるのだろうと思いませんか?
そこで、新しい問いを立てます。
Q.経済的な豊かさ、健康寿命、頼れる親戚・友人の有無の間にはどのような関係があるか?
仮説はたくさん考えられます。
・経済的に豊かになると、健康管理にお金を使う余裕が出てくるから?
・健康でいられる年齢が長い、つまり仕事をできる期間も長くなることで、1人あたりGDPも増加するから?
・頼れる親戚・友人の有無というのは、頼る側と頼られる側がいて成立します。なので、1人あたりGDPが高い、つまり経済的余裕があると、頼られた時に支援できるということかもしれません。
このように1つのグラフを眺めるだけで、新しい仮説がどんどん出てきます。あくまでこれらは仮説ですから、正しいかはわかりません。データを見ながら自分で考え、新しい仮説を作り、次にどんなグラフを描いたら知りたいことがわかるだろう!と考えることこそ、データサイエンスの楽しさです。
データだけ眺めていてもわからないこともたくさんあります。そのため、実際の分析では先行研究を調べたり、仲間と議論したりします。今回の幸福度調査では、アカデミックな記事を探すのも手ですが、少し目先を変えて、Dollar Streetというウェブサイトを見てみましょう。このウェブサイトを使えば、世界中の暮らしを垣間見ることができます。
https://www.gapminder.org/dollar-street
例えば、幸福度ランキングで最下位になったジンバブエのお家と上位のデンマーク、スウェーデン、スイスのお家を見てみましょう。

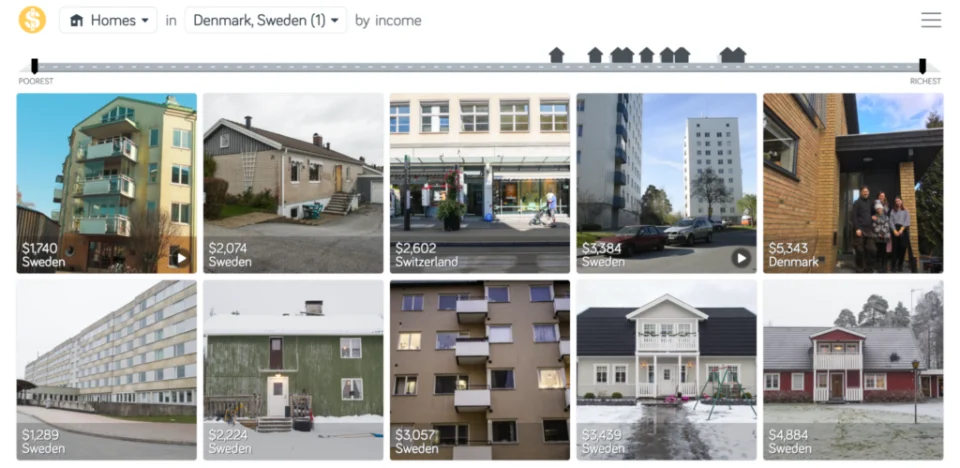
このように、データとの対話を通じて、世界のことを少し知って、また興味が湧いてくる。こんな営みが、データサイエンスの楽しいところだと思います。
そして、どんどん調べていくと、新しい問いに至ると思います。それは、「複数要素の中で重要なものはどれか?」という問いです。例えば、今回のデータで言えば、「幸福度(Life Ladder)」に強く影響を与えるのは、「1人あたりGDP」、「頼れる親戚・友人の有無」、「健康年齢」、「人生の自由度」のうち、どれか?といったことです。この場合、回帰分析という統計解析の手法を使うことで、分析することができます。その際、大事なことは、「分析結果はこうなるだろう」という分析者の「読み」を持っておくことです。言い換えれば、分析者自身が、データを眺め、背景も調べていくことで、「幸福度」、「1人あたりGDP」、「頼れる親戚・友人の有無」、「健康年齢」、「人生の自由度」の相互の関係について仮説を持っておくことであると言えます。その分析者の「読み」があるから、分析結果を見た時に「なるほど!思った通りだ!」と感じたり「意外な結果だ・・・ちゃんと見てみよう」と思ったりして、それが新しい発見に繋がっていくわけです。
データサイエンスって面白そう!と思っていただければ嬉しい限りです。
最後に参考までにRのコードを掲載しておきます。
ちなみに、今回の分析には、Rという統計解析ソフトを使っています。データミックスの講義でも学びますが、たった数行のコードで、データ操作やグラフ作成、統計解析ができるのでとても便利です。
# 必要なライブラリをインストールする
install.packages(“tidyverse”) install.packages(“GGally”) library(tidyverse) library(GGally)
# データを読み込む
whr<-read_csv(“DataPanelWHR2021C2.csv”)
# 2020年の結果を抽出する
whr2020<-whr %>%
filter(year==2020)
# 幸福度の上位の国を確認する
whr2020 %>%
arrange(desc(`Life Ladder`)) %>%
select(`Country name`, `Life Ladder`)
# 幸福度の下位の国を確認する
whr2020 %>%
arrange(`Life Ladder`) %>%
select(`Country name`, `Life Ladder`)
# 散布図行列を描く
whr2020 %>%
select(“Life Ladder”,
“Log GDP per capita”,
“Social support”,
“Healthy life expectancy at birth”,
“Freedom to make life choices”) %>%
ggpairs()
関連記事
ピックアップ
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…

データサイエンティストが資格を取得するメリットとおすすめの資格5選
データサイエンティストは、データを活用してビジネスや社会…
とは?難易度や勉強方法を解説.png)
統計検定データサイエンス基礎(DS基礎)とは?難易度や勉強方法を解説
統計検定データサイエンス基礎(DS基礎)は、データサイエ…

データサイエンスとは? 活用可能な領域や何が変わるかを解説
現代社会においては、あらゆる業界で日々膨大な量のデータが…

DX人材の育成事例とそれが急務である理由とは
情報通信白書(2022)における企業約3,000社への調…

もし営業(セールス)担当者がデータサイエンスを学んだら
データサイエンスのビジネス活用としては、データドリブン経…

データサイエンティストはなくなる職業という誤解?
データサイエンティストという職業が誕生し注目が集まり始め…

「データサイエンティスト育成のフロンティア」 立川 裕之
トップセールスからデータサイエンティストへ転身。 「人…
インタビュー
ランキングRANKING
WEEKLY週間
MONTHLY月間

