




データサイエンティスト
2024/03/01
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…
![]()
データサイエンスが学べる
日本屈指のビジネススクール「datamix」

データサイエンス
2020.10.20
この記事では、弊社のデータサイエンティスト育成本講座の卒業発表テーマの事例をご紹介します。卒業発表は、約6ヶ月間体系的にデータサイエンスを学んだ集大成として、受講生ひとりひとりが自ら設定した課題に取り組み、他の受講生や卒業生などデータミックスのコミュニティに属する人々に成果を発表するイベントです。
かねてより、「内容をぜひ紹介して欲しい」という声を方々で頂いていたのにお応えして、本日は、先日2020年9月13日に行われた2020年2月期生の卒業発表より、上場株式の銘柄選定課題を取り上げ、ご説明いたします。

発表者の宮崎さんは証券会社勤務で、機関投資家に日本株の銘柄を提案することを主な仕事にされています。
そこで課題となっているのが、提案する銘柄の選定に膨大な時間と労力がかかること。
今回の卒業発表では、年に3回公表される四半期報告書と年に1回公表される有価証券報告書のテキスト情報部分を数値化、各銘柄の決算内容を可視化することで、銘柄の選定をこれまでよりも短時間で効率的に行い、提案銘柄数を増やすという目標に取り組まれました。
ではこの課題をどのようなアプローチで解決していくのか、まずは仮説を立てます。

宮崎さんの仮説は、
文書にネガポジを付与することで、取材企業を一気に絞り込めるのでは!?
というものです。
「文書にネガポジを付与する」、というのは聞き慣れない言葉かもしれませんので少し説明したいと思います。
宮崎さんのこの発表ではテキスト情報を扱った分析を行います。テキスト情報を始めとする私たちが普段使用している言語のことを自然言語というのですが、この自然言語をコンピュータで処理させる一連の技術のことを自然言語処理と呼びます。そして、この自然言語処理を用いて行なう分析手法の一つに感情分析というものがあり、これは文章の中にある単語などからその文章がネガティブなものかポジティブなものかを判断するというものです。
宮崎さんが仮説で言っている「文書にネガポジを付与する」というのはつまり、テキスト情報を使用した感情分析を行ない、文書がネガティブなものかポジティブなものか判断するという事を指しています。
(Polarityという言葉が出てきますが、これはネガティブ・ポジティブの度合いを表します)
宮崎さんのスライドを参考に、実際に今回「ネガポジを付与する」というのがどのような事を行なうのか見てみましょう。

1つ目の文では赤字の「営業利益」や「経常利益」という単語が増収増益にかかっているため、こういった単語をポジティブと判断します。またそれらが8ヶ所あるため、Polarityは+8になります。
3つ目の文は「農薬中間体の出荷数量」という言葉が増加にかかっているため、この単語はポジティブ(+1)ですが、「医薬中間体」「電子材料の出荷数量」が減少、売上高が減収と、ネガティブと判断されるものが3ヶ所(-3)あるため、この文章のPolarityは-2となります。

まずは、検証するためのデータを収集します。
有価証券報告書・四半期報告書のデータは金融庁がEDINET(Electronic Disclosure for Investors’ Network)という電子開示システムで公開、APIも提供しているため、こちらから取得したようです。
予測モデルの作成には自分でデータを収集せず、chABSA-dataset(チャブサ・データセット) というデータセットを利用されたようです。
chABSA-datasetとはTIS株式会社が感情解析を行うために無償公開しているデータセットで、上場企業の有価証券報告書(2016年度)をベースに各文に対してネガティブ・ポジティブの感情分類だけでなく、「何が」ネガティブ・ポジティブなのかという観点を表す情報も含まれたデータセットとのことで、今回のモデル作成で使用するのにはまさにもってこいのデータセットです。
こういったデータセットは有償/無償 法人/個人 問わずインターネット上に様々なものが公開されているので、自分の目的にあったものが見つかるようであれば有効活用すると非常に効率的に予測モデルの作成やデータ分析が行えます。
自然言語処理を使用して感情分析を行なう際には予測モデルを作成する前にもう一つ、ベクトル化という作業が必要になります。
詳細な説明は割愛しますが、分析や予測モデルの作成の際など、計算が行えるように自然言語を数値化することをベクトル化といいます。ベクトル化には単語をどのように捉えて数値化するかによっていくつもの手法が存在しています。
今回宮崎さんは、TD-IDFとword2vecという2つの手法でベクトル化を、線形回帰、決定木、ランダムフォレストという3つの手法で予測モデルの作成を行い、TD-IDFでベクトル化しランダムフォレストで作成した予測モデルが最も精度が良いという結果になったようです。
予測モデル作成に使用した線形回帰、決定木、ランダムフォレストという3つの手法についても細かい説明についてはこの場では割愛しますが、3つとも統計学の教科書には必ずといって良いほど載っている機械学習と呼ばれる分野の代表的なアルゴリズムです。
実際の業務でも最初から採用する手法を一つに決めてしまわず、いくつかの手法を試してみた上で最も精度が良かったものを採用するという方法はよく取られています。
予測モデルの作成を行ったら、EDINETで取得した2019年度の有価証券報告書と四半期報告書の内容を使用して検証します。
Polarityの付与は文章単位で行なわれるため、各銘柄単位でのPolarityを算出するという作業も必要になります。ここでは文章ごとのPoralityの値を平均して銘柄単位でのPolarityとされています。(スライド10ページ目分析アプローチ⑦参照)
結果は以下のスライドのようになりました。

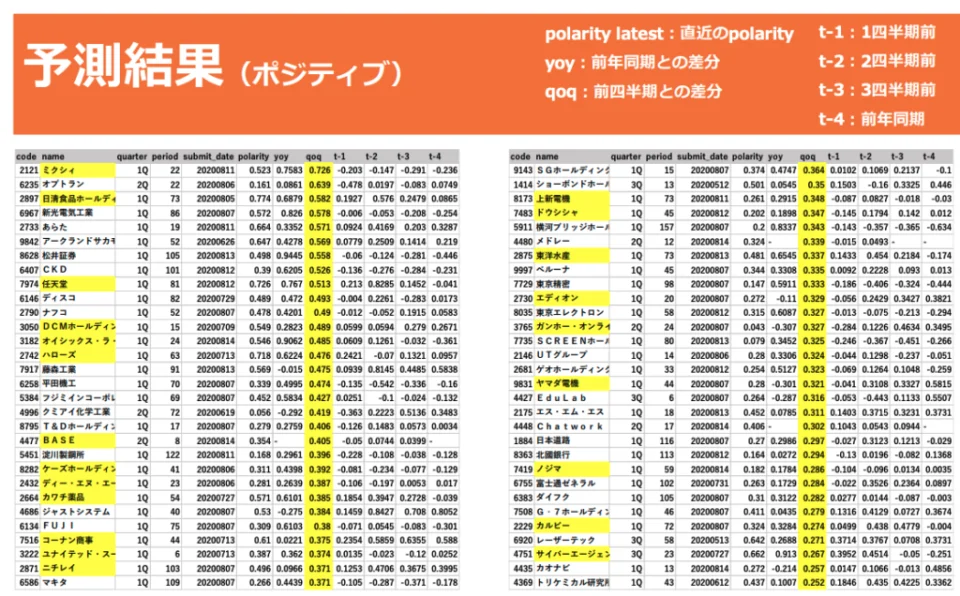

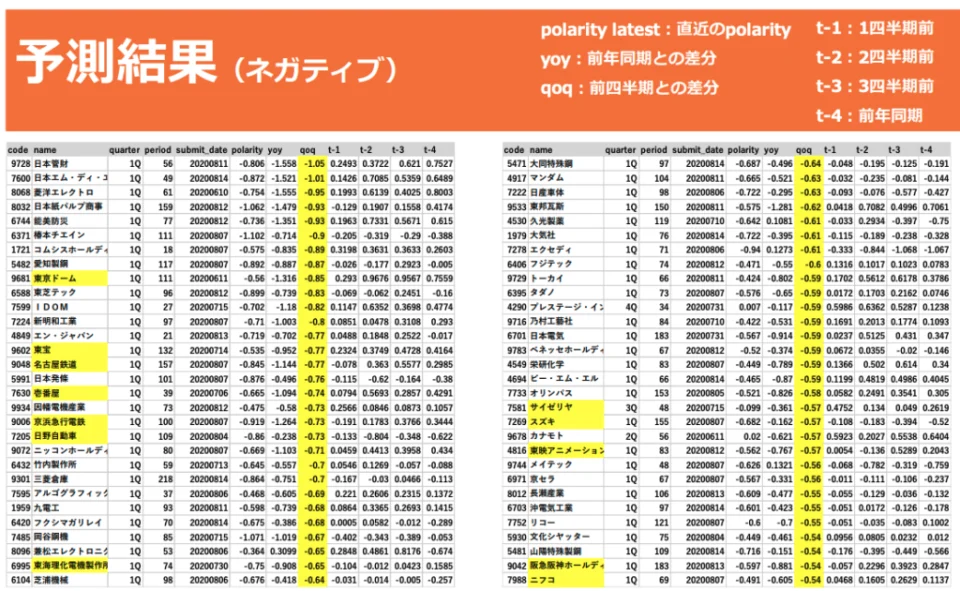

この結果から、宮崎さんは予測結果と内容に違和感はないと結論づけています。
素人判断とは違い、普段実際に業務をされている宮崎さんが違和感なしと判断出来るというのは非常に精度の良い予測モデルが作れた事の証であり、素晴らしい結果といえるのではないでしょうか。
宮崎さんは今回さらに、ビジネスインパクトやこの分析をどう活かすかといったところまでまとめています。

データ分析の知識やスキル以外にビジネス視点を持つということは非常に大事なことで、このように分析の結果はどのように生かせるのか、どれ位の効果が見込めるのか、という視点は実際の業務でも常に意識しておきたい点です。
卒業発表の内容として、このような軸でしっかりとまとめられるのは、宮崎さんがこれまでの講座で常にこれらの点を意識しながら課題に取り組んで来た結果の表れといえると思います。
宮崎さんの実務の課題を通して業務でのデータサイエンス活用の流れがイメージ出来る点や、結果の精度の良さ、データを活用する上で意識したい点までもしっかりとまとまっているとても良い発表でした。
関連記事
ピックアップ
データサイエンティストになるためには? 必要なスキルや学習方法を解説
データサイエンティストとは、データを分析してビジネスに役…

データサイエンティストが資格を取得するメリットとおすすめの資格5選
データサイエンティストは、データを活用してビジネスや社会…
とは?難易度や勉強方法を解説.png)
統計検定データサイエンス基礎(DS基礎)とは?難易度や勉強方法を解説
統計検定データサイエンス基礎(DS基礎)は、データサイエ…

データサイエンスとは? 活用可能な領域や何が変わるかを解説
現代社会においては、あらゆる業界で日々膨大な量のデータが…

DX人材の育成事例とそれが急務である理由とは
情報通信白書(2022)における企業約3,000社への調…

もし営業(セールス)担当者がデータサイエンスを学んだら
データサイエンスのビジネス活用としては、データドリブン経…

データサイエンティストはなくなる職業という誤解?
データサイエンティストという職業が誕生し注目が集まり始め…

「データサイエンティスト育成のフロンティア」 立川 裕之
トップセールスからデータサイエンティストへ転身。 「人…
インタビュー
ランキングRANKING
WEEKLY週間
MONTHLY月間

